一、扯淡部分
回想当年,在摆脱写页面时js全靠从各种DEMO中copy出来然后东拼西凑的幽暗岁月之后,毅然决然地打算放弃这种处处“拿来主义”的不正之风,然后开启通往高大上的“前端攻城狮”的飞升之旅。想想都有些小激动呢~然而人生不如意者十之八九,刚踏上征程就经常会被各种Error虐到体无完肤,有时候甚至会被在现在看来很低级的bug折磨得生不如死。但没有一种成长是不需要付出代价的,也就是那段刚跳入泥潭的日子开启了让自己成为一名真正的JSer的大门,也使自己在奔向高大上的路上让“见招拆招、兵来将挡”成为常态,以至于后来都慢慢觉得,做一个东西不遇上几个bug心里就没有稳妥扎实的安全感。再后来也就学着不断去安慰自己:踩到脚底下的bug越多,离翻过那座墙也就不远了~
回望一路走来的林林种种,有一个bug大概是每个JSer在初入大门时都遇到过的。那就是用js获取页面元素的时候经常会报出一个TypeError:Cannot read property ‘XXX’of null.大意就是根本就没找到你要找的元素,更别说你要对它进行操作了。明明页面上有这个元素,但在js里偏偏获取不到,这让很多刚接触js不久的童鞋都伤透了脑筋,于是疯狂百度谷歌,最后才发现造成这个低级bug的始作俑者竟然是window.onload,也就是文档未就绪,DOM树还没有建完就开始对节点进行操作从而导致的错误。
扯了那么多,终于扯到跟本文主题相干的东西了:domReady,也就是所谓的“文档就绪”。我们对DOM节点的任何操作在DOM树创建之后就可以进行。在理解这个概念之前,我们先来看看浏览器在载入一个文档时是怎么对HTML进行解析的。
二、浏览器渲染引擎的HTML解析流程
何谓“渲染”,其实就是浏览器把请求到的HTML内容显示出来的过程。渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。下面是渲染引擎在取得内容之后的基本流程:
1,解析html以构建dom树(构建DOM节点):渲染引擎开始解析html,并将标签转化为内容树中的dom节点。
2,构建render树(解析样式信息):解析外部CSS文件及style标签中的样式信息。Render树由一些包含有各种属性的矩形组成,它们将被按照正确的顺序显示到屏幕上。
3,布局render树(布局DOM节点):执行布局过程,它将确定每个节点在屏幕上的确切坐标。
4,绘制render树(绘制DOM节点):Render树构建好了之后,将会再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
以上就是HTML渲染的基本流程(详情请移步至“浏览器内部工作原理”),但这并不包含解析过程中浏览器加载外部资源如图片、脚本、iframe等的过程。说白了,上面的四步仅仅是HTML结构的渲染流程,而外部资源的加载在HTML结构的渲染流程中贯穿始终,即便绘制DOM节点已经完成,外部资源依然可能正在加载中或尚未加载。
三、window.onload
了解了浏览器渲染引擎的HTML解析流程,我们就回到domReady。前文提到了,那个蛋疼的TypeError是由于在DOM树构建完成之前对节点进行了操作,而通常的解决的办法就是让js在window.onload的回调里执行,也就是说,在文档所有的解析渲染、资源加载完成之前,不让js脚本执行,这样一来就妥妥地避免了因js操作先于DOM树创建而带来的bug:
1 | Window.onload = function(){ |
这样的解决办法应该是初学原生js时很多人最常用的解决办法,看起来也的确没什么问题。如果文档外部资源不多的时候也没什么问题,但,我们来做一个假设。假设一个页面上有100张远程图片,我需要让js做到在点击每张图片时alert出图片的src属性,又该怎么做?
是不是已经发现点小问题了?按照第二部分内容对浏览器解析渲染HTML流程的介绍,DOM树很快就构建完毕了,而100张图片还在缓慢地加载。而要想执行alert出图片src属性的js,则需要等到100张图片全部加载完成后才能执行。而在这期间,页面元素不会响应你的任何操作,就好像“死”了一样。如果是在实际项目中,用户很可能不会等到你页面所有东东加载完以后才去操作,在面对一个不会对自己的操作做任何响应的页面,唯一比较解气的方式就是——果断关掉~然后……就没有了然后。
所以在实际应用中,我们经常会遇到这样的场景,让页面加载后去做一些事情:绑定事件、DOM操作某些结点等。使用window.onload对于很多实际的应用而言有点太“迟”了,比较影响用户体验。那有没有更好的方法解决这个问题?比如提前到只要DOM树创建完成之后就可以进行如上操作呢?答案当然是有的:DOMContentLoaded事件。
四、DOMContentLoaded
说这个之前必须要提一下jQuery中的domReady机制。很多时候在使用jq也会出现最前面出现的那个TypeError,解决办法就是把js放到jQuery的ready回调里:
1 | $(document).ready(function(){...}); |
或者:
1 | $(function(){...}); |
这样一来,错误妥妥地没了。然后对比因果关系,大概得出一个结论:jQuery的ready回调应该跟window.onload的效果原理是一样的。恩,应该是这样。那我们就先来看一看jQuery(1.11.1)的ready回调是如何实现的:
1 | jQuery.fn.ready = function( fn ) { |
看起来比想象中的window.onload要复杂呵。Jq的源码中出现了DOMContentLoaded、readyState、onreadystatechange,这些跟domReady有什么关系?
我们还是先从DOMContentLoaded说起吧。就如前面所述,很多时候我们会把js逻辑写在window.onload回调中,以防DOM树还没有建完就开始对节点进行操作从而导致错误,而对于很多实际应用来说,越早介入对DOM的干涉就越好,比如进行特征侦测、事件绑定、DOM操作神马的。domReady还可以满足用户提前绑定事件的需求,因为有些情况下页面的图片等外部资源过多,window.onload迟迟不能触发,这时若还没有绑定事件,用户点任何的按钮都没反应(链接除外)会直接影响体验。
为了解决window.onload的短板,FF中便增加了一个DOMContentLoaded方法,与onload相比,DOMContentLoaded方法触发的时间更早,它是在页面的DOM树创建完成后(也就是HTML解析第一步完成)即触发,而无需等待其他资源的加载。Webkit引擎从版本525(Webkit nightly 1/2008:525+)开始也引入了该事件,Opera中也包含该方法。到目前为止NB的IE仍然没有要添加的意思。虽然IE下没有,但解决办法总是有的。于是对于那些忙前忙后的兼容小达人和死不悔改的顽固派,也就有了两套策略:
1)支持DOMContentLoaded事件的,就使用DOMContentLoaded事件;
2)不支持的,就用来自Diego Perini发现的著名Hack兼容。兼容原理大概就是,通过IE中的
document.documentElement.doScroll(‘left’)来判断DOM树是否创建完毕。
Blabla了这么多,来看个IE模拟DOMContentLoaded例子吧。这个例子就来自上面发现IE下doScroll Hackd的作者,细看也就是简化版的jQuery.ready回调的IE处理逻辑。
1 | function IEContentLoaded (w, fn) { |
而对于高大上的chrome、ff等高级浏览器来说,对DOMContentLoaded事件的处理就相对来说小case了,按照标准的事件绑定方式就可以处理:
1 | if ( document.addEventListener ) { |
五、实例
看到这,想必大家已经对DOMContentLoaded已经有了新的认识,onload保险丝也该适时换成智能电门啦~接下来就来个鲜活的例子,来让大家更清晰的做下对比。
首先,页面上有一组图片:
1 | <ul> |
页面的js处理逻辑:
1 | <script> |
相信js脚本不用做过多解释,在前面都已做过详细分析,我们直接来看运行结果:
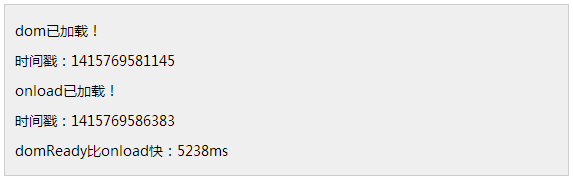
很容易就能看出,DOMContentLoaded执行5238ms之后才执行的onload。这只是一个DEMO的差距,而如果是更大型的应用,可能这个时间差距会更大。
最后
这就是本文所分享的domReady引入的机制,有兴趣的可以继续移步如下链接。希望本文能为你提供到帮助,也希望与读者多多交流。如文中内容有误,请评论告知~谢谢。
浏览器内部工作原理:
http://kb.cnblogs.com/page/129756/
司徒正美《javascript的事件加载》:
http://www.cnblogs.com/rubylouvre/archive/2009/08/26/1554204.html